AI search that understands your company documents.
Upload any rough or unstructured data, from PDFs and tables to books, images, videos, and more, and get your queries answered without the risk of inaccurate responses.
Talha made a hard document product simple to explain, sell, and use.
— Product team, Levitate Data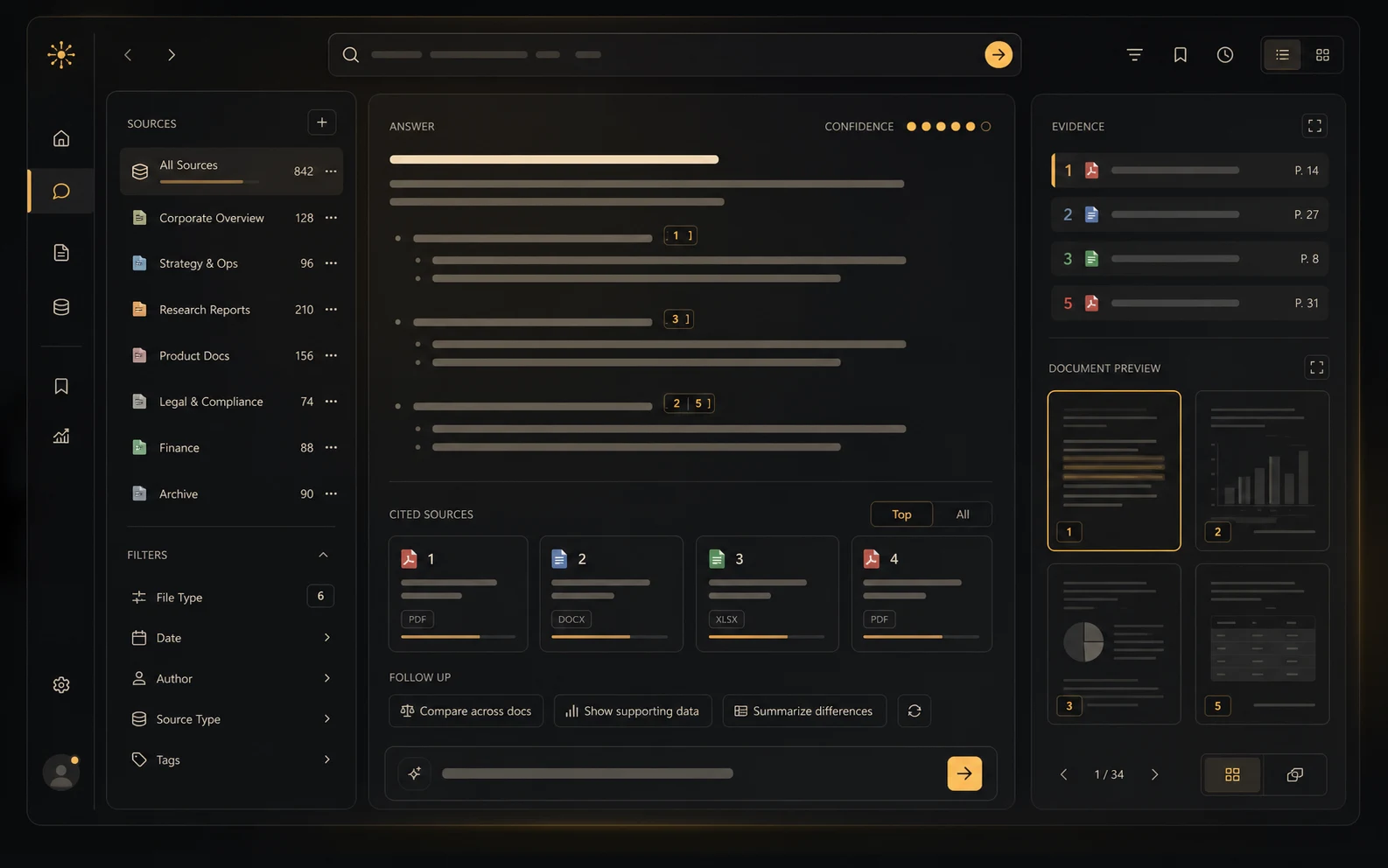
Performance you can trust
Trusted at scale
Delivered in 6 months
Driving results from day one
Most question-and-answer systems fail when producing accurate answers.
Company data is stored in various messy format such as PDF's, scans, images, tables and media.
Thalamus provides one clear path for uploading this data and getting your questions answered with proper citations.
Important company knowledge is spread across PDFs, scans, tables, videos, and files that keep changing.
People need to see where an answer came from before they rely on it for important decisions.
Policies, contracts, and product details get updated regularly, so answers need to stay up to date.
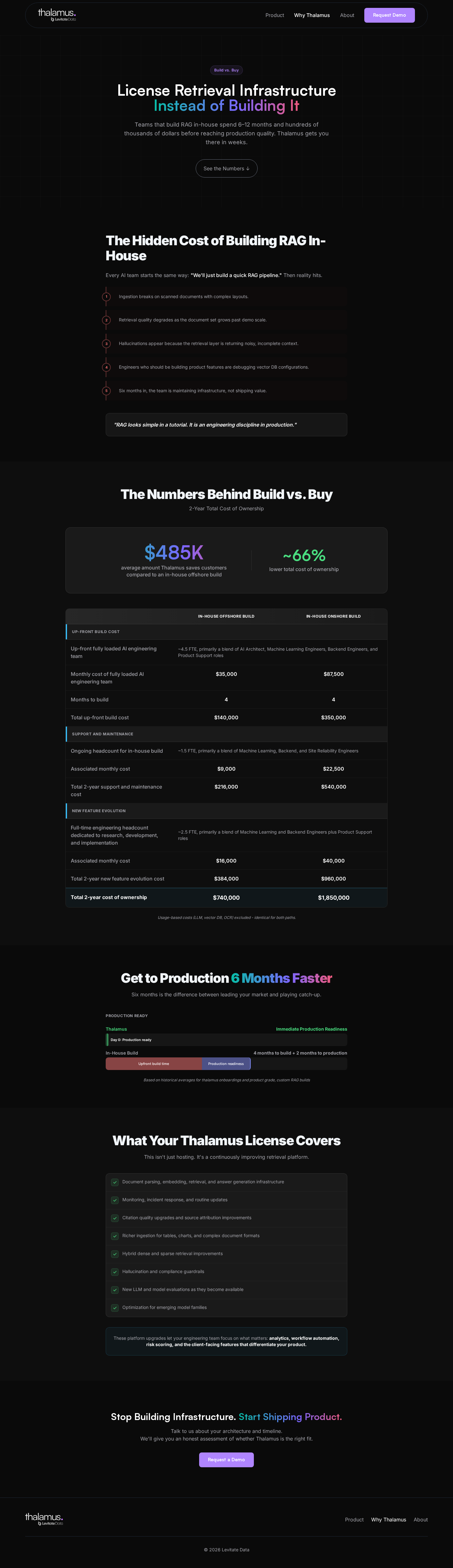
The page had to clearly show the cost, time, and effort saved by using Thalamus instead of building everything from zero.
We showed Thalamus as the place where teams can ask questions from company knowledge.
The message became simple: add your files, ask a question, see the source, and control who can access what.
The buyer case focused on faster answers, easier trust, and less work to maintain.
- Reliable answers, not basic search.
- Support for messy formats and layouts.
- Source links for quick verification.
- Privacy, access, and audit controls.
- Clear buy-vs-build proof.
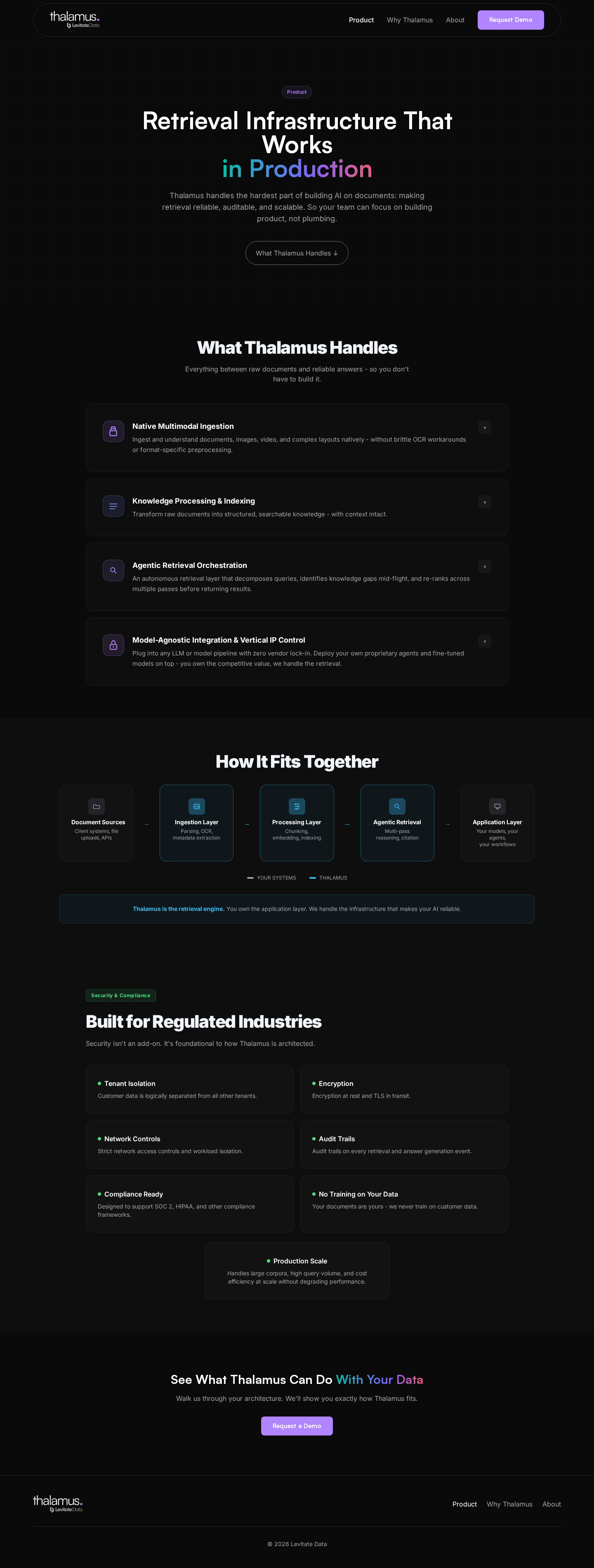
Document pipeline
Unified ingestion for scans, tables, layouts, and media.
Source-backed answers
Answers with citations, confidence, and a full audit trail.
Privacy first
Access controls and sensitive-data handling built in.
Buy-vs-build framing
Cost, timeline, and maintenance packaged for faster decisions.
Product story
Thalamus became an answer layer, not a search box.
Launch narrative
Clear pages that communicate value and drive buyer confidence.
Discovery + audit
Reviewed materials, competitors, and buyer concerns.
Core narrative
Defined the answer-layer positioning.
Product pages
Shaped the homepage, walkthrough, and why page.
Buyer proof
Simplified the cost and savings case.
Launch assets
Prepared sales copy and demo messaging.
Go live
Launched and refined the messaging.

- Company systems
- File uploads
- Tool links
- Rich media
- PDFs
- Scans
- Tables
- Images + video
- Questions
- Gaps
- Best sources
- Citations
- Chat
- Workflows
- Reports
- History
Thalamus handles the document-answering layer: cleanup, source links, and reliability.
Clearer product story: Thalamus now reads as a focused document-answer product for teams that need proof.
Sharper buyer case: move faster, reduce risk, and avoid maintenance drag.
Talha made a hard document product simple to explain, sell, and use.
- Company systems
- File uploads
- Tool links
- Rich media
- PDF parsing
- OCR + scans
- Table extraction
- Images + video
- Source search
- Citation links
- Confidence scores
- Knowledge gaps
- Chat interface
- Workflows
- Reports
- History
- Access controls
- Audit trails
- Privacy rules
- Compliance
Got a problem AI might solve? Let's find out.
30 minutes. Free. No NDA needed. You leave with a clear yes-or-no on whether to build — and a one-pager you can forward to your team the same day.